恾侾丂尨惗惗暔忣曬僒乕僶乮擔杮岅斉乯
URL, http://protist.i.hosei.ac.jp/index-J.html
|
岞奐島墘夛丗惗暔懡條惈尋媶丒嫵堢傪巟偊傞峀堟僨乕僞儀乕僗 |
|
尨惗惗暔忣曬僒乕僶 http://protist.i.hosei.ac.jp/index-J.html | |
| 妛弍尋媶偵偍偗傞僀儞僞乕僱僢僩偺桳梡惈偲惗暔懡條惈DB偺峴曽 | |
| 寧堜梇擇乮朄惌戝妛 帺慠壢妛僙儞僞乕乯 | |
| 侾丂尨惗惗暔忣曬僒乕僶偺徯夘 |
| 1-1丂僨乕僞儀乕僗峔抸偺栚揑 |
|
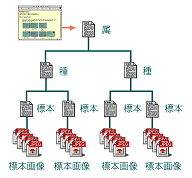
丂乽尨惗惗暔忣曬僒乕僶乿偼1995擭偐傜峔抸傪巒傔丆摨擭偵夋憸僨乕僞儀乕僗偲偟偰僀儞僞乕僱僢僩忋偱岞奐偟偨丅惂嶌幰偼寧堜乮朄惌戝乯丆栘尨乮朄惌戝乯丆塋愳乮媨忛嫵堢戝乯偺嶰柤偱丆夋憸偺嶌惉丆Web pages偺曇廤傪寧堜偑丆惷巭夋丒摦夋曇廤僔僗僥儉偺奐敪丆屆暥專僨乕僞儀乕僗乮屻弎乯偺峔抸傪栘尨偑丆偦偟偰丆僱僢僩儚乕僋偺娗棟傪塋愳偑扴摉偟偰偄傞丅峔抸偺栚揑偼丆條乆側尨惗惗暔偺夋憸傗婰嵹忣曬傪僱僢僩儚乕僋忋偱岞奐偟丆峀偔悽奅拞偺恖乆偵棙梡偟偰傕傜偆偙偲偵偁傞乮恾侾乯丅
|
恾侾丂尨惗惗暔忣曬僒乕僶乮擔杮岅斉乯 URL, http://protist.i.hosei.ac.jp/index-J.html |
丂偨偩偟丆峔抸摉弶偼丆帺暘払偺庤嫋偵偁傞夋憸丆偡側傢偪尋媶偺夁掱偱嶌惉偟偨傕偺偺榑暥摍偱巊梡偣偢偵巆偭偨幨恀側偳傪庡側僨乕僞儀乕僗壔偺懳徾偵偟偰偄偨丅偦偺偨傔丆岞奐偟偨夋憸偼幚尡偵巊傢傟傞傾儊乕僶傗僝僂儕儉僔側偳偛偔傢偢偐側惗暔庬偵尷傜傟偰偄偨丅偟偐偟丆偄偞岞奐偟偰傒傞偲丆棙梡幰偺懡偔偼堦斒偺恖乆偱偁傝丆愱栧揑側抦幆傪摼傞偙偲傛傝傕丆尨惗惗暔偵娭偡傞婎杮揑側抦幆丆偦偺拞偱傕偲偔偵暘椶忣曬傪媮傔偰傾僋僙僗偟偰偔傞偙偲偑傢偐偭偨丅幮夛偼尨惗惗暔偵娭偡傞暘椶僨乕僞儀乕僗傪昁梫偲偟偰偄偨偺偱偁傞丅
丂偙傟偼惂嶌幰偺堦恖偱偁傞巹乮寧堜乯偵偲偭偰偼乽搉傝偵廙乿偩偭偨丅側偤側傜丆巹偼傕偲傕偲尨惗惗暔偺恑壔偵嫽枴偑偁偭偨偐傜偱偁傞丅恑壔傪尋媶偡傞偵偼暘椶妛偺抦幆偑晄壜寚偩偑丆巹偼偦傟傑偱偼暘椶偵偼傑偭偨偔娭怱偑側偔丆僨乕僞儀乕僗峔抸摉弶偼丆帺暘偺尋媶嵽椏偱偁傞僝僂儕儉僔傗傾儊乕僶埲奜偵偳傫側尨惗惗暔偑偄傞偐傎偲傫偳抦傜側偐偭偨丅偦偙偱丆栐梾揑側暘椶僨乕僞儀乕僗傪嶌傟偽丆帺暘偵偲偭偰傕尨惗惗暔偺暘椶傪妛廗偡傞傛偄婡夛偵側傞偺偱偼側偄偐偲峫偊傞傛偆偵側偭偨偺偱偁傞丅
丂偲偼偄偊丆摦暔傗怉暔偱乽栐梾揑側暘椶僨乕僞儀乕僗乿傪嶌傠偆偲偡傟偽丆悽奅拞傪偐偗夞偭偰僒儞僾儖傪嵦廤傕偟偔偼嶣塭偟側偗傟偽側傜側偄偩傠偆丅偙傟偼偲偰傕屄恖儗儀儖偱偱偒傞巇帠偱偼側偄丅偟偐偟丆尨惗惗暔偺応崌偼丆偦偺彫偝偝屘偵懠偺惗暔偱偺忢幆偑墲乆偵偟偰捠梡偟側偄偙偲偑偁傞丅巹偺応崌偼偦傟偑岾偄偟偨丅偲偄偆偺偼丆尨惗惗暔偺懡偔偼丆僐僗儌億儕僞儞丆偡側傢偪丆宍懺揑偵摨庬偲尒側偣傞惗暔偑悽奅拞偵峀偔暘晍偟偰偄傞偺偱偁傞丅偙傟偼尵偄姺偊傞偲丆尷傜傟偨応強傪挷傋傞偩偗偱丆悽奅拞偱抦傜傟偰偄傞悢懡偔偺庬偑敪尒偱偒傞偙偲傪堄枴偡傞丅懡偔偺楯椡偲旓梡傪偐偗偰悽奅拞傪嬱偗夞傜側偔偲傕丆恎嬤側抮傗徖丆偁傞偄偼挰拞偺壓悈摴側偳偐傜僒儞僾儖傪嵦廤偡傞偩偗偱栐梾揑側僨乕僞儀乕僗偑嶌傟傞乮壜擻惈偑偁傞乯偺偱偁傞丅
丂偦偙偱丆幚嵺偵悢擭慜偐傜丆栰奜嵦廤偟偨尨惗惗暔傪曅抂偐傜嶣塭偟偰丆偦偺柤慜傪挷傋夋憸偲偲傕偵僨乕僞儀乕僗偵慻傒崬傓嶌嬈傪峴偆傛偆偵側偭偨丅
| 1-2丂僨乕僞儀乕僗傪嶌傞堄媊 |
丂埲忋偺傛偆偵丆摉弶偼帺暘払偺尋媶慺嵽乮夋憸摍乯傪岞奐偡傞偙偲傪栚揑偲偟偰僗僞乕僩偟偨乽尨惗惗暔忣曬僒乕僶乿偩偭偨偑丆搑拞偐傜暘椶僨乕僞儀乕僗偲偟偰偺惈奿傪嫮傔偰偄偭偨丅偦傟偲偲傕偵丆巹帺恎偺尨惗惗暔偺暘椶偵娭偡傞抦幆傕憹偊丆抦幆偺憹壛偵敽偭偰暘椶妛偵懳偡傞嫽枴傕崅傑偭偨丅傑偨丆偦偺夁掱偱埲壓偺傛偆側尨惗惗暔偵偍偗傞暘椶僨乕僞儀乕僗偺昁梫惈偲偦偺堄媊偵婥偯偔偙偲偑偱偒偨丅
|
仜尨惗惗暔偺懡偔偼曐懚昗杮偑嶌傟側偄 丂妅傪帩偮尨惗惗暔偺拞偵偼丆偦偺妅偺宍偱庬傪摨掕偱偒傞傕偺偑偄傞丅偟偨偑偭偰丆偦偺応崌偼妅傪曐懚昗杮偲偟偰棙梡偡傞偙偲偑偱偒傞丅偟偐偟丆傎偲傫偳偺尨惗惗暔偼妅傪傕偨偢巰偸偲摨帪偵偦偺宍傪幐偭偰偟傑偆乮恾俀乯丅偙偺偨傔丆曐懚昗杮傪嶌傞偺偼嬌傔偰擄偟偔丆懠偺惗暔偺傛偆偵昗杮偵棅偭偨暘椶傪峴偆偙偲偑偱偒側偄丅傗傓側偔丆廬棃丆尨惗惗暔偺暘椶偼婰嵹偲慄夋偵棅偭偰峴傢傟偰偒偨偑丆偙偺偙偲偑尨惗惗暔乮偲偔偵尨惗摦暔乯偺暘椶傪崿棎偝偣傞堦場偵傕側偭偰偄偨丅
|
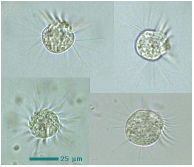
恾俀丂慇栄拵偺堦庬 Halteria grandinella
|
丂偦偙偱峫偊傜傟傞偺偑丆惗偒偨忬懺偺嵶朎傪幨恀傗摦夋偵婰榐偟曐懚昗杮偺懼傝偲偟偰棙梡偡傞曽幃偱偁傞丅栜榑丆偄偐偵惛鉱側夋憸偱偁偭偰傕杮暔偺昗杮偺姰慡側懼傢傝偵偼側傜側偄丅偟偐偟丆尦乆曐懚昗杮偑嶌傟側偄尨惗惗暔偱偁傟偽丆夋憸傪婰榐偡傞偙偲偑嵟椙偺慖戰巿偱偁傞偺偼娫堘偄側偄丅傑偨丆夋憸傪僨僕僞儖壔偟偰僱僢僩儚乕僋忋偱岞奐偡傟偽丆悽奅拞偺扤傕偑梕堈偵尒傞偙偲偑偱偒傞丅偙傟偼曐懚昗杮偵偼側偄桪傟偨摿挜偱偁傝丆偙傟偵傛偭偰尨惗惗暔偺暘椶偵娭偡傞抦幆偺晛媦偑懀恑偝傟傞偼偢偱偁傞丅偝傜偵偄偊偽丆壖偵崱屻崙撪偁傞偄偼悽奅奺抧偵偄傞尨惗惗暔尋媶幰偑帺暘払偺廃埻偵偄傞尨惗惗暔傪嵦廤丒嶣塭偟偰変乆偲摨條側僨乕僞儀乕僗傪岞奐偡傟偽丆偦傟傜偺夋憸傪僱僢僩忋偱斾妑丒専摙偡傞偙偲偱丆暘椶妛尋媶偦偺傕偺偵傕栶棫偰傞偙偲偑偱偒傞偺偱偼側偄偐偲婜懸偟偰偄傞丅
| 拲侾乯丂旝惗暔偺応崌偼丆惗偒偨惗暔偦偺傕偺傪乽宯摑曐懚乿偟偰丆偦傟傪婎弨偵庬偺摨掕傪峴側偆偙偲傕偁傞丅偟偐偟丆宯摑曐懚偝傟偰偄傞偺偼婛抦庬偺偛偔堦晹偵夁偓偢丆偡傋偰偺庬傪宯摑曐懚偡傞偺偼尰幚揑偵偼傎傏晄壜擻偲尵偭偰傛偄丅傑偨丆宯摑曐懚偡傞応崌偼丆栰奜偲摨偠攟梴忦審傪妋曐偡傞偺偑擄偟偄偨傔丆攟梴偟偰偄傞娫偵嵶朎偺宍懺傗惗棟妛揑摿挜偑曄壔偟偰偟傑偆偙偲傕偁傞丅 |
仜恎嬤偵偨偔偝傫偺庬椶偑偄傞
丂婛弎偟偨傛偆偵丆尨惗惗暔偺懡偔偼僐僗儌億儕僞儞偱偁傞丅偙傟偼巹偺傛偆偵栐梾揑側僨乕僞儀乕僗傪嶌傠偆偲偡傞幰偵偲偭偰偼僒儞僾儖傪廤傔傗偡偄偺偱搒崌偑傛偄偑丆堦斒揑偵偼旕忢偵傗偭偐偄側摿挜偲偄偊傞丅
丂悽奅拞偱偼偙傟傑偱偵侾係侽枩埲忋偺惗暔庬偑敪尒偝傟丆枹敪尒偺傕偺傕娷傔傞偲3000枩丆偁傞偄偼1壄偲偄偭偨朿戝側悢偵側傞偲尵傢傟偰偄傞偑丆東偭偰変乆偺擔忢惗妶傪峫偊傞偲丆帺暘偺栚偺撏偔斖埻偵偄傞摦暔傗怉暔偺庬椶偼偛偔尷傜傟偰偄傞丅偦偺偨傔丆嬤強偺愳傗椦偱捁傗崺拵丆嫑側偳傪娤嶡偡傞嵺偵偼丆巗斕偺僈僀僪僽僢僋傪壗嶜偐梡堄偡傟偽捠忢偼廫暘帠懌傝傞丅
|
丂偟偐偟丆尨惗惗暔偺応崌偼丆偦偆偄偆栿偵偼偄偐側偄丅嬤強偺抮傗悈偨傑傝偐傜丆傢偢偐悢廫ml偺悈傗揇傪嵦廤偡傞偩偗偱傕丆偦偺僒儞僾儖偐傜偼悽奅拞偵暘晍偡傞悢懡偔偺庬偑尒偮偐傞壜擻惈偑偁傞偐傜偩丅幚嵺丆僈僀僪僽僢僋偳偙傠偐愱栧彂傪壗嶜挷傋偰傕丆懏柤偡傜傢偐傜側偄尨惗惗暔偵憳嬾偡傞偙偲偼寛偟偰婬偱偼側偄乮恾俁乯丅
丂偐傝偵恎嬤偵偄傞尨惗惗暔傪庬偺儗儀儖傑偱偒偪傫偲摨掕偟傛偆偲偡傞側傜丆偦傟傑偱偵敪昞偝傟偨尨惗惗暔偺暘椶偵娭偡傞偡傋偰偺暥專傪丆尨挊榑暥傑偱娷傔偰丆庤嫋偵抲偄偰偍偐側偗傟偽側傜側偔側傞丅偟偐偟丆偦傟偼偁傑傝偵旕尰幚揑側榖偱偁傞丅堦曽丆僨乕僞儀乕僗偵偦傟傜偺朿戝側忣曬傪拁愊偟僱僢僩偱岞奐偡傟偽丆扤傕偑庤寉偵偦傟傜偺忣曬傪棙梡偟偰丆嵦廤偟偨尨惗惗暔偺庬椶傪挷傋傞偙偲偑偱偒傞丅
|
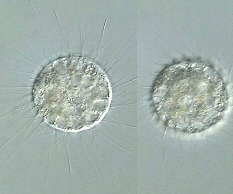
恾俁丂強懏晄柧偺尨惗惗暔
|
仜偨偔偝傫偄偰傕堦搙偵娤嶡偱偒傞偺偼偛偔傢偢偐
丂恎嬤偵偨偔偝傫偺庬椶偑偄傞偲偼偄偊丆幚嵺偵偦傟傜傪娤嶡偡傞偲側傞偲榖偼暿偱偁傞丅傢偢偐側僒儞僾儖偱偁偭偰傕丆偦偙偵偄傞偡傋偰偺尨惗惗暔傪娤嶡偡傞偺偼帠幚忋晄壜擻偲尵偭偰傛偄丅捠忢丆尠旝嬀娤嶡梡偺僾儗僷儔乕僩偵偺偣傜傟傞悈偺検偼懡偔偰傕0.1 ml偐偦傟埲壓偱偁傞丅偙傟偩偗嬐偐側僒儞僾儖偱傕偦偺慡懱傪娤嶡偟廔偊傞偵偼憗偔偰傕10暘掱搙偼偐偐傞丅偲側傞偲 1 ml偺悈傪偔傑側偔娤嶡偡傞偵偼100暘側偄偟2帪娫掱搙偼偐偐傞偲偄偆寁嶼偵側傞乮拲俀乯丅椺偊偽 1 t乮僩儞丟1000儕僢僩儖乯偺悈偺拞偵1000旵偺尨惗惗暔偑偄偨偲偟偰傕丆侾儕僢僩儖摉傝偱偼傢偢偐1旵偵偟偐側傜側偄丅偙偺傢偢偐侾旵傪敪尒偡傞偩偗偱傕扨弮寁嶼偱嵟戝2000帪娫傕旓傗偝側偗傟偽側傜側偄偙偲偵側傞丅娽偺慜偵1000旵乮屄懱乯傕惗暔偑偄傟偽丆摦暔傗怉暔側傜愨懳偵尒摝偡偙偲偼側偄偼偢偩偑丆尨惗惗暔偺応崌偼傎偲傫偳偄側偄偺偲摨慠側偺偱偁傞丅
| 拲俀乯丂僝僂儕儉僔傗傾儊乕僶僾儘僥僂僗側偳戝宆偺尨惗惗暔偱偁傟偽丆掅攞棪偺幚懱尠旝嬀偱斾妑揑娙扨偵尒偮偗傞偙偲偑偱偒傞丅偟偐偟丆偙傟傜偼歁擕椶偱尵偊偽丆僝僂傗僋僕儔偺傛偆側傕偺偱丆尨惗惗暔偺拞偱偼偐側傝摿庩側晹椶偵懏偡傞丅懠偺悢懡偔偺尨惗惗暔偼幚懱尠旝嬀偱偼偦偺懚嵼偡傜妋擣偱偒側偄偺偱丆400攞偁傞偄偼偦傟埲忋偺攞棪偱娤嶡偡傞昁梫偑偁傞丅偦偺偨傔堦搙偵娤嶡偱偒傞検偑偛偔尷傜傟偰偟傑偆偺偱偁傞丅 |
丂偝傜偵丆捠忢丆懡偔偺尨惗惗暔偼僔僗僩偲屇偽傟傞宍偱媥柊偟偰偄傞偨傔娤嶡偟偢傜偄偲偄偆栤戣傕偁傞丅栰奜偺娐嫬偼曄壔偑寖偟偄偺偱丆尨惗惗暔偼帺暘偺惗堢偵揔偟偨忦審偵側偭偨帪偵僔僗僩偐傜弌偰慺憗偔憹怋偟丆娐嫬偑埆壔偡傞偲嵞傃僔僗僩偺拞偵擖偭偰惗偒巆傝傪偼偐偭偰偄傞丅僔僗僩壔偟偨尨惗惗暔傪娤嶡偡傞偵偼丆僔僗僩偐傜弌偰憹怋偟傗偡偄娐嫬傪嶌偭偰傗傜側偗傟偽側傜側偄偑丆偡傋偰偺庬椶偵懳偟偰偦偺傛偆側忦審傪嶌傞偺偼帠幚忋晄壜擻偱偁傝丆偦偺堄枴偱傕嵦廤偟偨僒儞僾儖偱娤嶡偱偒傞傕偺偼偛偔堦晹偵尷傜傟偰偟傑偆偺偱偁傞丅
丂偙偺傛偆側惈幙傪帩偭偰偄傞偨傔丆偙傟傑偱尨惗惗暔偺庬偺懡條惈偵偮偄偰偼廫暘偵棟夝偝傟偰棃側偐偭偨丅偦偙偱丆娤嶡偟偨僒儞僾儖偺夋憸傪挿擭彮偟偢偮偱傕僨乕僞儀乕僗偵拁偊偰偄偗偽丆屻乆偵側偭偰奺惗暔庬偛偲偺庬撪曄堎偺尋媶摍偵栶棫偰傞偙偲偑偱偒傞偼偢偱偁傞丅
| 1-3丂僨乕僞儀乕僗偺嶌傝曽 |
|
丂偝偰丆偦傟偱偼偳偺傛偆偵偟偰乽尨惗惗暔僨乕僞儀乕僗乿傪嶌偭偰偄傞偐偵偮偄偰偩偑丆偙傟偵娭偟偰偼丆偡偱偵埲壓偺URL偱堦斒岦偗偺夝愢偲偟偰徻嵶偵弎傋偰偄傞偺偱偙偙偱偼偛偔娙扨偵嶌惉庤弴偩偗傪徯夘偡傞丅
夋憸丒摦夋嶌惉巟墖 丂傑偢丆栰奜偐傜嵦廤偟偰偒偨僒儞僾儖傪尠旝嬀偱娤嶡偟丆偦傟傑偱偵嶣塭偟偨偙偲偺側偄庬椶傗丆偁傞偄偼偡偱偵嶣塭偟偨庬偱偁偭偰傕丆嵦廤抧偑堎側偭偰偄偨傝丆宍懺揑側曄壔偑傒傜傟傞傕偺偵偮偄偰偼壜擻側偐偓傝幨恀嶣塭乮応崌偵傛偭偰偼摦夋傕嶣塭乯傪峴側偆乮恾係乯丅
|
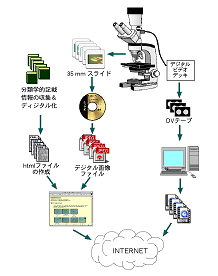
恾係丂僨乕僞儀乕僗偺嶌傝曽 |
|
丂嶌惉偟偨JPEG夋憸僼傽僀儖偼僼僅僩CD偛偲偵傑偲傔偰僨乕僞儀乕僗偵慻傒崬傓丅堦曽丆奺夋憸偛偲偺嵦廤抧丆擭寧丆嶣塭幰摍偺婎慴僨乕僞偲偦偺惗暔柤乮妛柤丟晄柧側応崌傕偁傞乯偐傜側傞婰嵹僨乕僞傪嶌惉偟丆偙傟偲奺夋憸偑攝抲偝傟偰偄傞URL偺僨乕僞傪崌懱偝偣偨夋憸昞帵梡偺html宍幃偺僥僉僗僩僼傽僀儖傪嶌惉偡傞丅
丂偮偓偵偙偺僥僉僗僩僼傽僀儖偵偁傞奺夋憸偺忣曬乮婰嵹忣曬偲夋憸偺URL乯傪嶣塭偝傟偨僒儞僾儖乮昗杮乯偛偲偵愗傝敳偄偰丆懏丒庬偺夝愢偑晅偄偨html僼傽僀儖偵揬晅偗傞丅偙偙偱怴偨偵嶌惉偝傟偨html僼傽僀儖偼昗杮偛偲偺夋憸傪昞帵偝偣傞偨傔偺乽昗杮Web page乿偲側傞丅偙偺屻丆偙傟傜偺昗杮Web page傪丆昗杮堦棗梡偺乽庬Web page乿偵儕儞僋偝偣丆偝傜偵偦傟偧傟偺庬Web page傪庬堦棗梡偺乽懏Web page乿傊偲儕儞僋偝偣傞丅偙偆偡傞偙偲偱丆棙梡幰偼懏偐傜庬傊偲儕儞僋傪扝偭偰嵟廔揑偵昗杮偛偲偺夋憸傪墈棗偱偒傞傛偆偵側傞乮恾俆乯丅
|
恾俆丂僨乕僞儀乕僗偺僼傽僀儖峔惉 |
| 1-4丂尨惗惗暔忣曬僒乕僶偺婎杮峔惉 |
|
丂埲忋偺傛偆偵丆乽尨惗惗暔忣曬僒乕僶乿偱婎杮偲側傞偺偼丆嵦廤乮偁傞偄偼攟梴乯偟偨奺昗杮乮嵶朎傑偨偼僋儘乕儞丆尰嵼栺4300僒儞僾儖乯偛偲偺夋憸偱偁傝丆偙傟傜傪暘椶懱宯偵偟偨偑偭偰庬丆懏偛偲偵傑偲傔偰惍棟偟偰偁傞丅
仜庡側儊僯儏乕
尋媶帒椏娰 丂昗杮夋憸偵偼丆儊僀儞儊僯儏乕偵偁傞乽尋媶帒椏娰乿偐傜傾僋僙僗偡傞偙偲偑偱偒傞丅偨偩偟丆尋媶帒椏娰偵偁傞忣曬偼搑拞傑偱偼擔杮岅偲塸岅偺椉曽偺夝愢偑偮偄偰偄傞偑丆嵟廔揑偵扝傝拝偔昗杮Web pages偼丆庬偺夝愢偐傜夋憸偺愢柧傑偱偡傋偰塸岅偱婰嵹偟偰偁傞丅偙傟偼丆擔杮岅斉偲塸岅斉偺椉曽傪嶌傞偺偑柺搢側偺偲丆尋媶帒椏娰偺棙梡幰偲偟偰偼婎杮揑偵尋媶幰傪憐掕偟偰偄傞偺偱丆棙梡幰偑擔杮恖偱傕尋媶幰側傜塸岅偺傒偱傕棙梡忋偼偝傎偳巟忈偼側偄偼偢偲偺峫偊偵傛傞乮恾俇乯丅
|

恾俇丂乽尋媶帒椏娰乿儊僯儏乕 |
丂側偍丆偙偺乽尋媶帒椏娰乿傪傛偔尒偰偄偨偩偔偲傢偐傞偺偩偑丆尰嵼偼丆尨惗惗暔偩偗偱側偔丆懡嵶朎偺摦暔傗尨妀惗暔偺夋憸傕傢偢偐偩偑岞奐偟偰偄傞丅偙傟偼尨惗惗暔偺嵦廤傪偡傞偲摨偠僒儞僾儖偺拞偵偙傟傜偺惗暔傕懡悢娤嶡偝傟傞偺偱丆側偵偘側偔嶣塭傪巒傔偨偺偑偒偭偐偗偲側偭偨丅僋儅儉僔傗儚儉僔丆僀僞僠儉僔丆儈僕儞僐偲偄偭偨旝彫懡嵶朎摦暔傗儐儗儌丆Merismopedia偲偄偭偨尨妀惗暔偵偮偄偰偼丆摉弶偼傑偭偨偔抦幆傕嫽枴傕側偐偭偨偑丆嶣塭傪懕偗傞娫偵丆尨惗惗暔偺帪偲摨條丆師戞偵嫽枴偑桸偒丆偐偮丆僱僢僩忋偵偼偙傟傜偺夋憸傪岞奐偟偰偄傞僒僀僩偑傎偲傫偳側偄偲偄偆帠幚偵婥晅偄偰偐傜偼愊嬌揑偵嶣塭偡傞傛偆偵側偭偨丅崱屻傕壜擻側偐偓傝偙傟傜偺夋憸傕廩幚偝偣偰偄偙偆偲峫偊偰偄傞丅
|
尨惗惗暔恾娪 乮 http://protist.i.hosei.ac.jp/taxonomy/menu.html乯 丂尋媶帒椏娰偼尋媶幰岦偗偵嶌偭偰偄傞偑丆僱僢僩儚乕僋傪夘偟偰傾僋僙僗偟偰偔傞偺偼尋媶幰偩偗偲偼偐偓傜側偄丅傓偟傠棙梡幰偺戝敿偼尋媶幰埲奜偺堦斒偺恖乆偱偁傞偲偄偭偰傛偄丅偦偙偱丆堦斒棙梡幰傊偺僒乕價僗偲偟偰丆尨惗惗暔偺暘椶偵娭偡傞娙扨側愢柧偲丆偦傟偵娭楢偟偨夋憸傪慻傒崌傢偣偨乽尨惗惗暔恾娪乿傕梡堄偟偰偁傞丅偨偩偟丆偙傟偼擔杮岅斉偺傒偱塸岅斉偼嶌惉偟偰偄側偄丅偦偺栿偼丆塸岅斉傑偱嶌惉偡傞梋桾偑側偄偲偄偆偺偑堦斣戝偒側棟桼偩偑丆偁偊偰晅偗壛偊傟偽丆僨乕僞儀乕僗傪峔抸偡傞忋偱岞揑側帒嬥偺墖彆傪庴偗偰偄傞偨傔偱傕偁傞乮慡偰偱偼側偄偑丆丆乯丅岞揑側帒嬥偲偼尦傪媻偣偽惻嬥偱偁傝丆偟偨偑偭偰乽尨惗惗暔恾娪乿偼僗億儞僒乕偱偁傞擺惻幰傊偺乽棙塿娨尦乿偱偁傞偲埵抲晅偗偰偄傞乮恾俈乯丅 |
恾俈丂乽尨惗惗暔恾娪乿儊僯儏乕 |
丂尨惗惗暔恾娪偱偼戙昞揑側惗暔偺夋憸偺傒傪徯夘偟偰偄傞偑丆奺懏偛偲偺夝愢偺儁乕僕偺嵟屻偵偼丆尋媶帒椏娰偵偁傞懏偛偲偺Web pages傊偺儕儞僋傕晅偗傜傟偰偄傞丅奺惗暔孮偺婎杮揑側摿挜傪棟夝偟偰丆屄乆偺惗暔偵偮偄偰傛傝徻偟偔抦傝偨偔側偭偨恖偺偨傔偺傕偺偱偁傞丅
摦夋僨乕僞儀乕僗
乮
http://protist.i.hosei.ac.jp/Movies/htmls/index.html乯
丂嵟嬤偼丆惷巭夋偩偗偱側偔丆尨惗惗暔偺摦夋僨乕僞傕捛壛偟偮偮偁傞乮尋媶帒椏娰乯丅偙傟偼丆幚嵺偵庬傪摨掕偡傞嵺偵偼丆偨傫偵偦偺宍懺揑摿挜偩偗偱側偔乽摦偒乿傕廳梫側敾抐婎弨偵側偭偰偄傞偙偲偵婥偯偄偨偨傔偱偁傞丅廬棃暘椶妛偱偼宍懺揑側摿挜偑庡側庬偺敾掕婎弨偲偝傟偰偒偨偑丆偦偺栿偼丆偨傫偵報嶞暔偱偁傞妛弍暥專偵偼摦夋偑婰榐偱偒偢丆懠偵摦夋傪婰榐偡傞偨傔偺揔摉側攠懱偑側偐偭偨偐傜丆偵偡偓側偄丅摦偒偺偍偍傑偐側摿挜偼暥專偵婰嵹偱偒偰傕丆暥復偱偼昞尰偟傛偆偺側偄旝柇側摦偒偼丆暘椶妛幰偺擼棤偵婰壇偝傟傞偩偗偱懠偵揱払偝傟傞偙偲偼側偐偭偨丅偟偐偟丆僱僢僩儚乕僋偱偼丆僥僉僗僩傗惷巭夋偩偗偱側偔摦夋傗壒傕婰榐偱偒傞偺偱丆崱屻丆暘椶妛偱偼偙傟傜偺忣曬傕暘椶宍幙偲偟偰棙梡偝傟偰偄偔傕偺偲梊憐偝傟傞丅
丂偨偩偟丆尰嵼岞奐偟偰偄傞摦夋偼丆僱僢僩儚乕僋偺捠怣懍搙傪峫椂偟偰丆傕偲偺DV摦夋傪偐側傝埑弅偟偰偄傞乮僼傽僀儖僒僀僘偼嵟戝偱500 k僶僀僩乣1 M僶僀僩掱搙乯丅偦偺偨傔嵶晹偺摦偒偑柧椖偱偼側偄丅傑偨丆帪娫傕抁偄僇僢僩偵梷偊偰偁傞偺偱丆庬偺摿挜傪攃埇偡傞忋偱偼晄廫暘偐傕抦傟側偄丅偩偑丆僆儕僕僫儖偺DV摦夋傕曐懚偟偰偁傞偺偱丆彨棃丆捠怣懍搙偑岦忋偟偨嬇偵偼丆偙傟傜偺DV摦夋僼傽僀儖乮悢廫M乣悢昐M僶僀僩乯傪偦偺傑傑岞奐偟偨偄偲峫偊偰偄傞丅
|
僀儊乕僕僽僢僋乮屆暥專僨乕僞儀乕僗乯 乮 http://protist.i.hosei.ac.jp/PDB/ImageBook/menu.html乯 丂惷巭夋傗摦夋偺懠偵丆尨惗惗暔偵娭偡傞婱廳偐偮婓彮側屆暥專偺夋憸僨乕僞儀乕僗壔傕峴側偭偰偄傞乮恾俉乯丅尨惗惗暔偺暘椶妛尋媶偼19悽婭乣20悽婭慜敿偵偐偗偰惙傫偵峴側傢傟偨丅偦偺寢壥丆尨惗惗暔偺庬偵娭偡傞婰嵹傕敿悽婭埲忋慜偺屆偄暥專偵偁傞傕偺偑懡偄丅偟偐偟丆偙傟傜偺屆暥專偼扤傕偑梕堈偵擖庤偱偒傞傕偺偱偼側偄偨傔丆庬偺摨掕傪偡傞嵺偺巟忈偵側偭偰偄偨丅偦偙偱丆挊嶌尃偺徚幐偟偨屆暥專偺奺儁乕僕傪僗僉儍僫偱夋憸壔偟偰Web 僽儔僂僓忋偱墈棗偱偒傞傛偆偵偟偨乮尋媶帒椏娰乯丅僨乕僞儀乕僗壔偺庤朄傕岞奐偟偰偄傞偺偱丆懠偱傕偙偺庤朄傪梡偄偰屆暥專偺僨僕僞儖壔丆僱僢僩儚乕僋岞奐偑恑傔偽丆暘椶妛尋媶偑傗傝堈偔側傞傕偺偲婜懸偟偰偄傞丅
|
恾俉丂乽僀儊乕僕僽僢僋乿儊僯儏乕 |
仜Google/Bio-Crawler傪棙梡偟偨僒僀僩撪専嶕
丂僨乕僞儀乕僗偲柫懪偭偰偄傞埲忋偼側傫傜偐偺専嶕婡擻偑偁傞偼偢偲巚傢傟傞偐傕抦傟側偄偑丆乽尨惗惗暔忣曬僒乕僶乿偼帺慜偺専嶕婡擻偼旛偊偰偄側偄丅偦偺懼傢傝偲偟偰丆奜晹偺専嶕僄儞僕儞傪棙梡偟偨乽僒僀僩撪専嶕乿偲偄偆庤朄傪摫擖偟偰偄傞丅
丂偙傟偼奜晹偺専嶕僄儞僕儞傪棙梡偡傞嵺偵丆偁傜偐偠傔専嶕懳徾傪帺暘偺僒僀僩偺傒偵尷掕偟偰専嶕傪峴側偆曽幃偱丆尰嵼偄偔偮偐偺専嶕僄儞僕儞偑桳彏乛柍彏偱偙偺傛偆側僒僀僩撪専嶕僒乕價僗傪採嫙偟偰偄傞丅偨偩偟丆堦斒岦偗偺専嶕僄儞僕儞乮摉僨乕僞儀乕僗偼Google傪棙梡偝偣偰傕傜偭偰偄傞乯偺応崌偼丆奺僒僀僩偵懳偟偰僨乕僞廂廤傪栐梾揑偵峴側偭偰偄傞偲偼偐偓傜側偄偺偱丆奜晹専嶕僄儞僕儞傪棙梡偟偨僒僀僩撪専嶕偱偼専嶕楻傟偑婲偙傞壜擻惈偑偁傞丅
丂偦偙偱丆嶐擭搙丆擾嬈惗暔帒尮尋媶強偑塣塩偡傞惗暔宯偺妛弍僒僀僩偵摿壔偟偨専嶕僄儞僕儞丆Bio-Crawler 乮http://bio-crawler.dna.affrc.go.jp/ 乯傪僒僀僩撪専嶕偵棙梡偱偒傞傛偆偵偡傞夵椙僾儘僕僃僋僩偵儐乕僓乕偺棫応偱嫤椡偟偨丅偙傟偵傛傝Bio-Crawler傪棙梡偟偨栐梾揑側僒僀僩撪専嶕偑偱偒傞傛偆偵側偭偨丅Bio-Crawler 偱偼丆捠忢偺慡暥専嶕偺懠偵丆儊僞僨乕僞乮html暥偺応崌偼儊僞僞僌偵婰嵹偝傟偨忣曬乯偺専嶕傕偱偒傞丅儊僞僨乕僞偲偟偰偼堦斒揑側Author丆 Description丆 Keywords偺懠偵丆惗暔宯撈帺偺傕偺偲偟偰 Field丆Organism傪帋尡揑偵愝掕偟偰偁傞丅
丂乽尨惗惗暔忣曬僒乕僶乿偼峀堟暘嶶宆岞嫟僨乕僞儀乕僗乮DPDD丆Distributed Public-Domain Database丆嶲徠丗Green, D. G. (1994). Databasing diversity - a distributed, public-domain approach. Taxon 43, 51-62. URL, http://life.csu.edu.au/~dgreen/papers/taxon.html 乯偺堦偮偲偟偰峔抸偟偰偄傞偑丆僱僢僩忋偱暘嶶偱偒傞偺偼僨乕僞偩偗偱側偔丆僨乕僞儀乕僗偺婡擻偦偺傕偺傕暘嶶偱偒傞偺偱偁傞丅乽栞偼栞壆乿側偺偱懠偵擟偣傜傟傞傕偺偼擟偣偰丆尋媶幰偼僨乕僞嶌傝偵愱擮偡傞曽偑朷傑偟偄偲峫偊偰偄傞丅
丂側偍丆偙偺Bio-Crawler 傪棙梡偟偨僒僀僩撪専嶕偺愝掕朄偵偮偄偰偼丆埲壓偺URL偱徻偟偔夝愢偟偰偄傞偺偱嶲徠婅偄偨偄丅
___ http://protist.i.hosei.ac.jp/Science_Internet/BioCrawler/index.html
仜夋憸採嫙幰乛嫤椡幰
乮
http://protist.i.hosei.ac.jp/PDB/contributors_J.html乯
丂婛弎偟偨傛偆偵丆搑拞偐傜僨乕僞儀乕僗峔抸偺栚揑傪栐梾揑側暘椶僨乕僞儀乕僗嶌傝偵僔僼僩偝偣偨偨傔丆嵟嬤偼帺暘偱嶣塭偟偨夋憸偑懡偔側偭偰偄傞偑丆偦傟偩偗偱側偔丆偙傟傑偱偵僱僢僩傪捠偠偰條乆側恖偐傜懡悢偺夋憸偺採嫙傪庴偗偰偄傞丅偦傟傜偺夋憸偼僨乕僞儀乕僗杮懱偵慻傒崬傓偲偲傕偵丆乽夋憸僊儍儔儕傿乿乮http://protist.i.hosei.ac.jp/PDB/Galleries/index.html乯偲偟偰奺採嫙幰偛偲偵夋憸傪堦棗偱偒傞傛偆偵偟偰偁傞丅
丂夋憸採嫙幰埲奜偵傕丆僱僢僩傪夘偟偰丆岞奐偟偨夋憸傪尒偰摨掕偺岆傝傪巜揈偟偰偔傟偨傝丆惗暔柤偑傢偐傜偢偵岞奐偟偰偁偭偨夋憸傪尒偰摨掕傪庤彆偗偟偰偔傟傞恖傕偄傞丅偝傜偵偼丆乽尨惗惗暔恾娪乿偺婰嵹乮嬠椶娭學乯偑屆偄偺偱怴偟偄傕偺偵彂偒姺偊偰偔傟偨恖傕偄傞丅
仜夋憸悢丆僼傽僀儖悢丆僨乕僞僒僀僘
丂尰嵼岞奐偟偰偄傞夋憸偼惷巭夋 栺30,000枃乮栺490懏丆1,600庬埲忋丆栺4,300僒儞僾儖乯丆摦夋 556僋儕僢僾偱偁傞丅婛弎偟偨傛偆偵丆惷巭夋偼墈棗梡偺僒儉僱僀儖夋憸偐傜儌僯僞偱偺墈棗梡拞宆夋憸丆報嶞梡偺戝宆夋憸傑偱俆抜奒偺堎側傞僒僀僘偺傕偺偑梡堄偝傟偰偄傞丅傑偨丆尦偺夋憸傪壛岺偟偰愢柧側偳傪彂偒壛偊偨傕偺傕奺懏丒奺庬丒奺昗杮偛偲偵偁傞丅偙偺偨傔丆惷巭夋偺僼傽僀儖悢偼夋憸枃悢偺俇攞埲忋偲側偭偰偄傞乮栺19枩屄乯丅摦夋傕惷巭夋偲摨條偵棙梡幰偺梫媮偵墳偠偰堎側傞係抜奒偺夋柺僒僀僘偺摦夋偑尒傟傞傛偆偵偟偰偁傞丅偨偩偟丆岞奐偟偰偄傞偺偼偛偔堦晹偱懡偔偼傑偩曇廤抜奒偵偁傞丅
丂堦曽丆尨惗惗暔恾娪偵偁傞夝愢暥梡偺html僼傽僀儖丆偍傛傃丆尋媶帒椏娰偵偁傞奺僒儞僾儖偛偲丆庬偛偲丆懏偛偲偺夝愢偲夋憸傪昞帵偝偣傞偨傔偺html僼傽僀儖偼丆崌寁偱栺9,000屄偁傞丅偦偟偰丆偙傟傜僥僉僗僩丆惷巭夋丆摦夋偺偡傋偰傪崌寁偟偨僨乕僞儀乕僗慡懱偺僨乕僞僒僀僘偼丆偍傛偦俋僊僈僶僀僩傎偳偱偁傞丅
| 1-5丂棙梡忬嫷丆棙梡幰偲偺岎棳 |
丂乽尨惗惗暔忣曬僒乕僶乿偼丆尰嵼丆朄惌戝 偺懠偵丆拀攇戝丆憤尋戝偺寁俁働強偵摨偠撪梕偺傕偺乮儈儔乕僒乕僶乯偑愝抲偝傟偰偄傞丅偄偢傟傕楢擔偐側傝偺傾僋僙僗偑偁傞偺偩偑丆尰嵼惓妋側傾僋僙僗悢偼攃埇偱偒偰偄側偄丅偲尵偆偺傕丆嵟嬤偼偁傑傝偵傾僋僙僗偑憹偊夁偓偰儘僌傪偲傞偺偑傑傑側傜側偔側偭偨偐傜偱偁傞丅
丂朄惌戝偺僒乕僶偺応崌丆崱擭巒傔崰傑偱偼傾僋僙僗乮僼傽僀儖傾僋僙僗乯傪婰榐偟偰偄偨偺偩偑丆嵟嬤偵側偭偰僒乕僶梡偺僷僜僐儞乮Macintosh G3乯偑昿斏偵僔僗僥儉僄儔乕傪婲偙偡傛偆偵側偭偨丅偙傟偵偼搑拞偱OS傪峏怴偟偨偙偲傕塭嬁偟偰偄傞傛偆側偺偩偑丆捈愙偺尨場偼傾僋僙僗偺媫憹偩偭偨丅婰榐偟偨偐偓傝偱偼侾擔偁偨傝嵟戝俋枩審偺傾僋僙僗偑偁偭偨偙偲傕偁傞丅偙傟偼暯嬒偡傞偲侾昩偵侾夞庛偺傾僋僙僗偵側傞偑丆傾僋僙僗偼忢帪堦條偵偁傞傢偗偱偼側偄丅傾僋僙僗偑廤拞偟偨帪偵僷僜僐儞偺張棟擻椡傪挻偊偰偟傑偄僄儔乕傪婲偙偟偨傜偟偄偺偱偁傞丅
丂偦偙偱丆崱擭偺搑拞偐傜偼僷僜僐儞傊偺晧壸傪嬌椡尭傜偡偨傔丆傾僋僙僗傪婰榐偡傞偙偲傪傗傔偨丅偙偆偡傟偽婰榐偡傞岺掱偑尭傞暘偩偗僒乕僶儅僔儞偑僼傽僀儖傾僋僙僗偵墳偊傞僗僺乕僪傕忋偑傞偺偱丆棙梡幰懁偐傜偡傟偽夋柺偺昞帵偑憗偔側傝棙梡偟傗偡偔側傞偲偄偆棙揰傕偁傞丅
丂偮偓偵幚嵺偵偳偺傛偆偵棙梡偝傟偰偄傞偐偵偮偄偰徯夘偡傞丅婛弎偟偨傛偆偵丆棙梡幰偺拞偵偼愱栧壠傕偄傞偺偱丆偙偺傛偆側恖乆偺拞偵偼丆崙撪奜偐傜儊乕儖摍傪夘偟偰夋憸傪採嫙偟偰偔傟偨傝丆庬偺摨掕偑晄妋偐側夋憸傪尒偰摨掕傪彆偗偰偔傟傞恖傕偄傞丅偟偐偟丆側傫偲偄偭偰傕堦斣懡偄偺偼丆堦斒偺棙梡幰偐傜偺夋憸偺棙梡婅偄傗丆庬偺摨掕埶棅側偳偺栤偄崌傢偣偱偁傞丅懡偄帪偵偼廡偵俁丆係夞偺昿搙偱栤偄崌傢偣偑偁傞乮嵟嬤偼丆奀奜偐傜偺栤偄崌傢偣偺曽偑懡偄乯丅僨乕僞儀乕僗偺惂嶌栚揑偼岞奐偟偨夋憸傪棙梡偟偰傕傜偆偙偲側偺偱丆偙傟偼惂嶌幰偲偟偰偼戝曄婌偽偟偄丅
丂偨偩偟丆婥偵側傞偺偼挊嶌尃偑傜傒偺栤戣偱偁傞丅夋憸傪棙梡偟偰傕傜偆偺偼偁傝偑偨偄偑丆偐偲尵偭偰夋憸偺嶣塭幰乮亖挊嶌尃幰乯偵柍抐偱岞偺応偱棙梡偟偨傝丆彜梡栚揑偵棙梡偝傟偰偼崲傞丅堦曽丆棙梡幰懁偐傜偡傟偽丆偳偆偡傟偽夋憸偑棙梡偱偒傞偺偐嫋壜忦審傗庤懕偒偺巇曽偑傢偐傜側偄偲棙梡偟偢傜偄丆偲偄偆恖傕懡偄偼偢偱偁傞丅偦偙偱丆棙梡偺嵺偺忦審傗庤懕偒偺巇曽傪徯夘偟偨乽挊嶌尃偵偮偄偰乿偲偄偆Web pages乮擔杮岅斉 http://protist.i.hosei.ac.jp/PDB/copyright_J.html 偲塸岅斉 http://protist.i.hosei.ac.jp/PDB/copyright_E.html 乯傕梡堄偟偰偁傞丅偦偟偰丆夋憸偑偁傞偡傋偰偺儁乕僕偱丆偦偙偵偁傞乽Copyright乿偲偄偆暥帤傪僋儕僢僋偡傟偽偙偺儁乕僕偑昞帵偝傟傞傛偆偵偟偰偁傞丅偙偺懠丆僨乕僞儀乕僗偵偁傞忣曬傪棅傝偵丆捈愙丆杮恖偑尋媶幒偵朘偹偰偔傞働乕僗傕懡偄丅
丂僨乕僞儀乕僗偺CD-ROM斉傪惂嶌偟偰柍彏攝晍偡傞妶摦傕峴側偭偰偄傞乮惓妋偵偼丆峴側偭偨乯丅1995擭偵戞堦斉傪惂嶌偟偰埲棃丆偙傟傑偱偵俀夞夵掶傪峴側偭偨偑丆戞嶰斉乮1999擭惂嶌乯偼栺7000枃傪攝晍偟偰慡崙偐傜條乆側斀嬁傪摼偨丅偨偩偟丆夋憸偑憹偊傞偵偮傟丆搑拞偐傜僱僢僩儚乕僋偱岞奐偟偰偄傞俆庬椶偺僒僀僘偺夋憸僼傽僀儖偡傋偰傪CD-ROM偵廂榐偡傞偙偲偑偱偒側偔側偭偨丅偦偺偨傔丆戞擇斉偐傜偼夋憸僼傽僀儖傪俀庬椶乮僒儉僱僀儖夋憸偲夋柺僒僀僘偺夋憸乯偺傒偵尭傜偟偰惂嶌偟偨丅偩偑丆戞嶰斉埲屻偼丆偝傜側傞夋憸偺憹壛偵傛傝夋憸僼傽僀儖偺庬椶傪嵟彫尷偵尭傜偟偰傕偡傋偰偺夋憸傪CD-ROM偵廂榐偱偒側偔側偭偨丅偙偺偨傔丆CD-ROM偺攝晍妶摦偼尰嵼拞巭偟偰偄傞丅
| 俀丂僱僢僩忋偱岞奐偝傟偨忣曬偺昡壙偲曐懚 |
| 2-1丂妛弍尋媶梡儊僨傿傾偲偟偰偺僱僢僩儚乕僋偺晄姰慡惈 |
丂埲忋偑乽尨惗惗暔忣曬僒乕僶乿偵偮偄偰偺徯夘偱偁傞偑丆偙偺傛偆側帺暘偨偪偺僨乕僞儀乕僗傪峔抸丒岞奐偡傞妶摦埲奜偵丆惗暔宯尋媶幰偵傛傞摨條側忣曬敪怣偑偝偐傫偵側傞傛偆條乆側妶摦傪峴側偭偰偄傞丅懠偺尋媶幰偑僨乕僞儀乕僗傪嶌傞偺傪庤揱偭偨傝乮憤尋戝嫟摨尋媶丆惗暔宍懺帒椏夋憸僨乕僞儀乕僗偺峔抸丆http://taxa.soken.ac.jp/乯丆僨乕僞儀乕僗峔抸偺偨傔偺巟墖僔僗僥儉傪奐敪偟偨傝傕偟偰偄傞乮壢妛媄弍怳嫽帠嬈抍丆惗暔宯尋媶帒嵽偺僨乕僞儀乕僗壔媦傃僱僢僩儚乕僋僔僗僥儉峔抸偺偨傔偺婎斦揑尋媶奐敪丆http://bio.tokyo.jst.go.jp/biores/index.htm 乯丅偝傜偵偼丆妛夛傗Web僒僀僩忋偱偺孾栔妶摦傕峴偭偰偄傞丅
丂偟偐偟丆巆擮側偑傜丆偙傟傑偱偺偲偙傠婜懸偡傞傎偳偵偼惗暔宯尋媶幰偐傜偺忣曬敪怣偼憹偊偰偄側偄丅偦偺尨場傪暘愅偟偨寢壥丆尋媶幰偑僱僢僩儚乕僋忋偱忣曬敪怣偡傞偙偲偵擬怱偱側偄偺偼丆偨傫偵Web page偺嶌惉朄傗僨乕僞儀乕僗偺峔抸朄側偳偵晄姷傟側偨傔丆偲偄偭偨媄弍揑側栤戣偵傛傞偺偱偼側偔丆傓偟傠丆幮夛僔僗僥儉忋偺栤戣偱偁傞偙偲偵婥偯偄偨丅偡側傢偪丆僱僢僩儚乕僋偵偼丆妛弍尋媶偵晄壜寚側俀偮偺梫慺丆岞奐偝傟偨忣曬傪乽昡壙乿偟乽曐懚乿偡傞偨傔偺幮夛揑巇慻傒偑寚偗偰偄傞偺偱偁傞丅偦偺偨傔丆僱僢僩忋偱岞奐偝傟偨忣曬偼丆尋媶幰偺嬈愌偲偟偰偼擣傔傜傟偢丆偦偺偙偲偑尋媶幰偐傜乽傗傞婥乿傪扗偭偰偄傞偺偱偼側偄偐偲峫偊傞傛偆偵側偭偨丅
丂偙偺栤戣偼丆懠偱徻偟偔徯夘偟偰偄傞偺偱乮http://protist.i.hosei.ac.jp/Science_Internet/WorkShop1999/JSZ_1999/index.html乯偙偙偱偼娙扨偵奣棯偺傒傪徯夘偡傞丅
丂傑偢丆廬棃偺壢妛偺僔僗僥儉偱偼丆尋媶幰偑惗嶻偟偨忣曬偼丆妛弍嶨帍摍偺報嶞儊僨傿傾傪夘偟偰岞奐偝傟傞丅偦偟偰丆岞奐偝傟偨傕偺偼戝妛恾彂娰摍偺岞揑婡娭偱峆媣揑偵曐懚偝傟傞丅妛弍忣曬偼丆偙偺傛偆側乽惗嶻乿偲乽岞奐乿偦偟偰乽曐懚乿偲偄偆俁偮偺梫慺乮側偄偟婡娭乯偑楢実偟偰偼偠傔偰妛弍忣曬杮棃偺婡擻傪壥偨偟摼傞偺偱偁傞丅傑偨丆岞奐慜偵丆榑暥怰嵏偲偄偆宍偱妛弍揑壙抣偺乽昡壙乿乮亖昳幙娗棟乯偑峴側傢傟丆堦掕偺昡壙傪摼偨傕偺偺傒偑岞奐偝傟傞乮恾俋乯丅
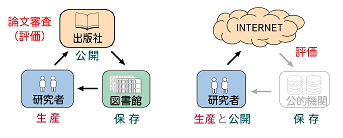
恾俋丂報嶞偲僱僢僩儚乕僋偺斾妑 |
丂偙偺傛偆側僔僗僥儉偑偁傞偙偲偱丆尋媶幰偺榑暥摍偑嬈愌偲偟偰擣傔傜傟丆備偔備偔偼偦傟偑條乆側宍偱尋媶幰帺恎偺棙塿偵傕偮側偑偭偰偄偔偺偱偁傞丅
丂堦斒偵丆惗嶻乮尋媶幰乯偲岞奐乮妛弍嶨帍乯偺栶妱偵偮偄偰偼擣抦偝傟偰偄傞偑丆戝妛恾彂娰摍偑壥偨偟偰偄傞曐懚偺栶妱偵偮偄偰偼堄幆偝傟傞偙偲偑彮側偄傛偆偱偁傞丅偩偑丆偙偺妛弍忣曬偺峆媣揑側曐懚偑側偝傟偰偙偦丆屻偵側偭偰榑暥摍偱堷梡偡傞偙偲偑壜擻偲側傝丆尋媶偺宲懕惈偑曐徹偝傟傞偺偱偁傞丅
丂偟偐偟丆廬棃丆僱僢僩儚乕僋忋偱岞奐偝傟偰偄傞妛弍忣曬偵娭偟偰偼丆DNA側偳堦晹偺椺奜傪彍偄偰丆偦傟傜傪塱懕揑偵曐懚偡傞偨傔偺岞揑婡娭偼懚嵼偟側偐偭偨丅僱僢僩儚乕僋忋偺忣曬偼丆岞奐屻偵撪梕偑彂偒姺偊傜傟偨傝丆僒僀僩偠偨偄偑偄偢傟偼徚柵偡傞壜擻惈偑崅偄丅偦偺偨傔丆撪梕偺擛壗偵娭傢傜偢丆榑暥摍偱堷梡偡傞偙偲偑偱偒偢乮傕偟偔偼堷梡偟偰傕柍岠偵側傞壜擻惈偑崅偄偺偱乯丆幚幙揑偵偼妛弍忣曬偲偟偰偺棙梡壙抣傪帩偨側偐偭偨乮帩偰側偐偭偨乯偺偱偁傞丅偦偟偰丆偦偺傛偆側忣曬傪敪怣偡傞妶摦傕尋媶幰偺嬈愌偲偟偰偙傟傑偱偼擣抦偝傟側偐偭偨丅嬈愌偵側傜側偗傟偽尋媶幰偵傗傞婥偑婲偙傜側偄偺傕柍棟偼側偄丅
丂傑偨丆忣曬偺惗嶻幰偑摨帪偵敪怣幰偵傕側傟傞偲偄偆偺偑僱僢僩儚乕僋偺婎杮揑摿挜偱偁傞埲忋丆報嶞儊僨傿傾偵偁傞傛偆側岞奐慜偺昡壙僔僗僥儉偼婎杮揑偵懚嵼偟偊側偄丅偙偺偨傔丆僱僢僩忋偵懚嵼偡傞忣曬偑偄傢備傞乽嬍愇崿岎乿偺忬懺偵側傞偺偼傗傓傪摼側偄丅偦偙偱丆報嶞儊僨傿傾偲偼堎側傞傗傝曽偱忣曬偺昡壙傪峴側偆昁梫偑偁傞偺偩偑丆偦偺傛偆側巇慻傒傕偙傟傑偱偼懚嵼偟側偐偭偨丅
| 2-2丂Wayback machine 偲 PageRank |
丂偟偐偟丆嬤擭丆忬嫷偼媫懍偵夵慞偟偮偮偁傞丅乽曐懚乿偵偮偄偰偼丆Internet Archive乮http://www.archive.org/乯偑丆偦偺廤傔偨朿戝側忣曬傪嶐擭枛偐傜岞奐偡傞傛偆偵側偭偨偙偲偺堄媊偑戝偒偄丅Internet Archive偲偼丆僱僢僩儚乕僋忋偵偁傞忣曬傪恖椶偺婱廳側楌巎堚嶻偲偟偰巆偡偙偲傪栚揑偲偟偰丆俇擭慜偐傜悽奅拞偺偁傝偲偁傜備傞僒僀僩偐傜廂廤壜擻側偡傋偰偺僨乕僞傪廤傔偰曐懚偡傞妶摦傪峴偭偰偄傞慻怐偱偁傞乮偙傟傑偱偵廂廤偟偨僨乕僞偼栺100僥儔僶僀僩梋両乯丅廬棃偼丆廂廤偟偨忣曬偺拞偵挊嶌尃傗僾儔僀僶僔乕偵娭學偡傞傕偺偑娷傑傟偰偄傞偲偄偆棟桼偱堦斒偵偼岞奐偟偰偄側偐偭偨偑丆嶐擭侾侾寧崰傛傝偡傋偰偺僨乕僞傪堦斒偵岞奐偡傞傛偆偵側偭偨丅偙偺Internet Archive偑廤傔偨僨乕僞傪墈棗偡傞偨傔偺僔僗僥儉傪Wayback machine偲偄偆乮http://protist.i.hosei.ac.jp/GBIF/DB_list/About_wayback.html 乯丅
丂偨偲偊偽丆乽尨惗惗暔忣曬僒乕僶乿偺応崌偼丆1997擭1寧偐傜廂廤偑巒傑偭偰偄傞偑丆偙偺摉帪偺URL偼http://mac2031.fujimi.hosei.ac.jp/index-J.html 偲偄偆傕偺偩偭偨丅偦偺屻丆2000擭4寧偵妛撪僱僢僩儚乕僋偺戝暆側曄峏偑偁傝丆偦偺嵺丆摉僒乕僶傕URL偺曄峏傪梋媀側偔偝傟偨乮曄峏屻偺URL偼http://protist.i.hosei.ac.jp/index-J.html乯丅偙偺娫傕Internet Archive偵傛傞僨乕僞廂廤偼掕婜揑偵峴側傢傟丆尰嵼偼怴媽偄偢傟偺URL偺僨乕僞傕墈棗壜擻偵側偭偰偄傞乮恾侾侽乯丅僨乕僞儀乕僗偺撪梕偼昿斏偵彂偒姺傢偭偰偄傞偨傔丆尰嵼丆惂嶌幰偱偁傞巹偺庤嫋偵偼1997擭摉帪偺Web page偺僨乕僞偼懚嵼偟側偄丅偩偑丆Internet Archive偵傾僋僙僗偡傟偽偦偺摉帪帺暘偑嶌偭偨Web page偑偳傫側傕偺偩偭偨偐傪尒傞偙偲偑偱偒傞乮拲丟弶婜偺崰偼夋憸偺廂廤偑晄姰慡偩偭偨偨傔丆1997擭崰偺Web page偺堦晹偼夋憸偺側偄傕偺傕偁傞乯丅
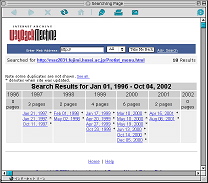
恾10a丂1997擭乣URL曄峏慜偺Web僨乕僞 URL, http://web.archive.org/web/*/ http://mac2031.fujimi.hosei.ac.jp/index-J.html
|
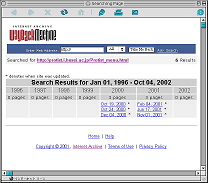
恾10b丂URL曄峏屻乣尰嵼偺Web僨乕僞 URL, http://web.archive.org/web/*/ http://protist.i.hosei.ac.jp/index-J.html
|
丂偙偺Internet Archive偺妶摦偵偼丆僾儔僀僶僔乕傗挊嶌尃曐岇側偳偺栤戣傕巆偝傟偰偼偄傞偑丆僱僢僩儚乕僋傪妛弍栚揑偱棙梡偟傛偆偲峫偊偰偄傞幰偵偲偭偰偼戝曄偁傝偑偨偄僒乕價僗偲偄偊傞丅側偤側傜丆偙傟偵傛傝丆恾彂娰偵廂憼偝傟偨妛弍暥專偲摨條丆僱僢僩儚乕僋忋偱岞奐偝傟偨忣曬傕埨怱偟偰榑暥摍偱堷梡偱偒傞傛偆偵側偭偨偐傜偱偁傞丅傛偭偰崱屻偼僱僢僩儚乕僋傪妛弍忣曬敪怣偺偨傔偺儊僨傿傾偲偟偰棙梡偡傞尋媶幰偑憹偊傞偙偲偑婜懸偝傟傞丅
丂堦曽丆昡壙乮忣曬偺昳幙娗棟乯偵娭偟偰偼丆専嶕僄儞僕儞 Google 乮http://www.google.co.jp/乯偑嵦梡偟偰偄傞PageRank偲偄偆専嶕寢壥傪弴埵晅偗偡傞巇慻傒偑拲栚偝傟傞丅専嶕僄儞僕儞偵偼怓乆側傕偺偑偁傞偑丆尰嵼丆悽奅偱傕偭偲傕棙梡幰偑懡偄偲尵傢傟傞偺偑Google偱偁傞丅偦偺棟桼偼丆廂廤偟偨忣曬検偺懡偝乮2002擭12寧尰嵼丆栺31壄web pages乯偲丆専嶕偺揑妋偝偵偁傞丅懠偺専嶕僄儞僕儞偺懡偔偼丆廂廤偟偨Web page偵偁傞僉乕儚乕僪偺埵抲傗悢側偳丆Web page偺撪梕傪暘愅偟偰丆専嶕寢壥傪弴埵晅偗偟堦棗昞帵偡傞曽幃傪偲偭偰偄傞丅偟偐偟丆偙偺曽幃偩偲丆Web僒僀僩偺惂嶌幰懁偑僉乕儚乕僪傪堄恾揑偵彂偒壛偊傞偙偲偱専嶕寢壥偺弴埵傪忋偘傞偲偄偭偨憖嶌偑偱偒偰偟傑偆丅偦偺偨傔丆専嶕偺僸僢僩悢偑懡偔側傟偽側傞傎偳丆棙梡幰偑扵偟偰偄傞忣曬偑尒偮偐傝偵偔偔側傞丆偲偄偆寚揰偑偁傞丅
|
丂偙傟偵懳偟偰丆Google偺PageRank曽幃偱偼丆奺Web page偵懳偡傞懠偺Web僒僀僩偐傜偺儕儞僋悢傪尦偵弴埵傪寛傔偰偄傞乮恾侾侾乯丅偦偺嵺丆儕儞僋傪挘偭偰偄傞僒僀僩帺恎偺PageRank傕峫椂偝傟傞丅偡側傢偪丆PageRank偺崅偄僒僀僩偐傜儕儞僋傪挘傜傟偰偄傞応崌偼偦偺儕儞僋偺億僀儞僩偼崅偔丆媡偵丆PageRank偺掅偄僒僀僩偐傜偺儕儞僋偼億僀儞僩偑掅偔僇僂儞僩偝傟傞丆偲偄偆嬶崌偱偁傞丅儕儞僋傪挘傞偲偄偆峴堊偼丆捠忢丆乽偙偺僒僀僩偼栶偵棫偮乿丆乽懠偺恖偵傕尒偣偨偄乿丆乽嶲峫偵偟偨乿側偳偺棟桼偱峴傢傟傞偺偱丆儕儞僋偵偼奺Web page傪幚嵺偵尒偨棙梡幰乮恖娫乯偺昡壙偑斀塮偝傟偰偄傞丆偲偄偊傞丅偙偺偨傔丆PageRank曽幃偼丆廂廤偟偨忣曬偑憹偊傟偽憹偊傞傎偳丆拲栚搙乮昡壙乯偺傛傝崅偄Web pages偑専嶕寢壥偺忋埵偵棃傞孹岦偑偁傝丆棙梡幰偼昁梫側忣曬傪摼傗偡偔側傞丆偲偄偆桪傟偨摿挜傪傕偮丅
|
恾11丂PageRank偺偟偔傒 |
| 拲俀乯丂揑妋偵専嶕偑偱偒傞偙偲偼棙梡幰偵偲偭偰偼曋棙偱偁傝偑偨偄偑丆偦偺寢壥偲偟偰丆堦曽偺忣曬傪敪怣偡傞懁偼戝曄尩偟偄嫞憟偵偝傜偝傟傞偙偲偵側傞丅椺偊偽丆偁傞僉乕儚乕僪傪娷傓Web pages偑悽奅拞偵悢愮丆悢枩偁偭偨偲偟偰傕丆棙梡幰偑墈棗偡傞偺偼丆専嶕寢壥偺忋埵10埵埲撪偐丆懡偔偲傕100埵掱搙傑偱偱偁傠偆丅偲側傞偲偦傟埲壓偵儔儞僋偝傟偨Web pages傪尒傞棙梡幰偼傎偲傫偳偄側偄偙偲偵側傞丅棙梡幰偑墈棗偟偰偦偺撪梕偑椙偄偲昡壙偝傟傟偽丆偦傟偼偦偺Web page傊偺儕儞僋悢偺憹壛偵偮側偑傞偺偱丆儔儞僋偺忋埵偵棃偨僒僀僩偵偼傑偡傑偡棙梡幰偑廤傑傝丆壓埵偺儔儞僋偺僒僀僩偲偺嵎偑奼戝偟偰偄偔偙偲偵側傞丅崱屻丆Google側偳偺専嶕僄儞僕儞傪棙梡偟偰忣曬傪扵偡恖偑憹偊傞偵偮傟丆偙偆偄偭偨忣曬棙梡偺堦嬌廤拞偼傑偡傑偡恑傓傕偺偲梊憐偝傟傞丅偙傟偼僀儞僞乕僱僢僩偺弌尰偵傛偭偰傕偨傜偝傟偨乽忣曬偺僌儘乕僶儖壔乿偺摿挜偺堦偮偲偄偊傞丅 |
丂偨偩偟丆Google偑廂廤懳徾偲偟偰偄傞偺偼妛弍忣曬偵尷掕偟偰偄傞栿偱偼側偄偺偱丆PageRank曽幃偵傛傞専嶕寢壥偺儕僗僩偺忋埵偵棃傞傕偺偑偦偺傑傑妛弍揑壙抣偺崅偝傪斀塮偟偰偄傞傢偗偱偼側偄丅偲偼偄偊丆専嶕偡傞嵺偺僉乕儚乕僪偲偟偰丆懠暘栰偱偼巊梡偝傟傞偙偲偑彮側偄愱栧惈偺崅偄妛弍梡岅傪巊偊偽丆偦偺専嶕寢壥偺忋埵偵棃傞傕偺偼偦傟側傝偵妛弍揑偵傕昡壙偝傟偨Web pages偱偁傞偲偄偊傞偼偢偱偁傞乮嶲峫丗http://protist.i.hosei.ac.jp/ProtistInfo/Records/Google.html 乯丅
| 俁丂惗暔懡條惈DB偺峴曽 |
| 3-1丂惗暔懡條惈娭楢Web僒僀僩挷嵏偵偮偄偰 |
丂傑偨丆崱夞偺島墘夛傪宊婡偵丆僱僢僩忋偵偁傞乽惗暔懡條惈娭楢Web僒僀僩乿偺挷嵏傕峴偭偨丅挷嵏偼Yahoo側偳偺僨傿儗僋僩儕僒乕價僗偵搊榐偝傟偨條乆側惗暔娭楢偺Web僒僀僩偺拞偐傜乽昗杮夋憸乿偲偟偰偺忣曬傪娷傓傕偺丆偡側傢偪丆夋憸偼偁傞掱搙偺戝偒偝偑偁偭偰丆奺惗暔偺摿挜偑幨偭偰偄傞偲巚傢傟傕偺丆偐偮丆奺夋憸偵偮偄偰偺婰嵹乮榓柤丆妛柤丆嶣塭幰丆嶣塭応強丆嶣塭忦審丆惗暔偺摿挜丆摍乆乯偑偁傞傕偺傪扵偡偙偲偐傜巒傑偭偨丅偟偐偟丆Yahoo側偳偺僨傿儗僋僩儕僒乕價僗偵搊榐偝傟偰偄傞偺偼慡懱偺偛偔堦晹偵偡偓側偄偺偱丆搑拞偐傜奺Web僒僀僩偵偁傞惗暔懡條惈娭楢儕儞僋傪扝偭偨傝丆偁傞偄偼丆忋婰偺Google側偳偺専嶕僄儞僕儞傪巊偄丆揔摉側妛柤傗榓柤傪擖椡偟偰丆摼傜傟偨専嶕寢壥偺拞偐傜奩摉偡傞Web僒僀僩傪偟傜傒偮傇偟偵扵偡丆偲偄偆曽幃傪嵦偭偨丅
丂挷嵏偼尰嵼傕宲懕拞偩偑丆偙傟傑偱偵慖傃偩偟偨偺偼栺400僒僀僩掱偱偁傞丅偦偺寢壥丆岞奐奐巒擭側偳偐傜敾抐偟偰丆嬤擭偙傟傜偺僒僀僩偺悢偑媫懍偵憹壛偟偮偮偁傞偙偲偑傢偐偭偨乮http://protist.i.hosei.ac.jp/GBIF/DB_list/index.html 乯丅
丂偙傟傜偺僒僀僩偺戝晹暘偼丆愱栧壠偑嶌惉偟偨傕偺偱偼側偔丆堦斒偺恖乆偑屄恖揑側嫽枴偐傜嶌惉丒岞奐偟偰偄傞傕偺偱偁傞丅偦偺偨傔丆愱栧抦幆傪栐梾偟偨傕偺偼彮側偄偑丆媡偵堦斒偺棙梡幰偵偲偭偰乮偦偟偰愱栧奜偺尋媶幰偵偲偭偰傕乯傢偐傝傗偡偔棙梡偟傗偡偄傕偺偑懡偄丅偟偨偑偭偰丆嫵堢梡偺儕僜乕僗偲偟偰偼廫擇暘偵栶棫偭偰偄傞偲偄偊傞丅
| 3-2丂僨僕僞儖昗杮傪廤傔偨峀堟僨乕僞儀乕僗偲偟偰偺棙梡 |
丂尰帪揰偱偼愱栧抦幆傪栐梾偟偨傕偺偑彮側偄偲偼偄偊丆奺Web僒僀僩偼帪娫偺宱夁偲偲傕偵撪梕偑廩幚偟偮偮偁傞偺傕傑偨妋偐偱偁傞丅偦偺昅摢偑丆崱夞偺岞奐島墘夛偺墘幰偱傕偁傞嶳揷傑偪巕偝傫偺乽旝彫奓乿偱偁傠偆丅岞奐楌俉擭乮惂嶌奐巒偐傜偩偲12擭両乯偺旝彫奓偵斾傋傞偲丆懠偺Web僒僀僩偼岞奐楌偑1, 2擭偺傕偺偑傎偲傫偳側偺偱丆撪梕揑偵偼偙傟偐傜偺傕偺偑懡偄偺偼傗傓傪摼側偄丅偟偐偟恾娪側偄偟偼僨乕僞儀乕僗偲偄偭偨丆偄傢備傞僐儗僋僞乕揑側梫慺傪傕偮僒僀僩偼丆帪娫偺宱夁偲偲傕偵惂嶌幰杮恖偺Web僒僀僩傊偺巚偄擖傟傕怺傑偭偰偄偔孹岦偑偁傞偺偱丆崱屻丆偡傋偰偱偼側偄偵偟偰傕丆懡偔偼幙丒検偲傕偵廩幚偟偰偄偔偲梊憐偝傟傞丅
丂傑偨丆偙傟傜偺Web僒僀僩偺惂嶌幰偼擔杮奺抧偵暘嶶偟偰偍傝丆奺乆偑帺暘偺廧傫偱偄傞抧堟偺惗暔傪庡側懳徾偵偟偰夋憸傪岞奐偟偰偄傞働乕僗偑懡偄丅偟偨偑偭偰丆屄乆偺Web僒僀僩偼栐梾揑偱偼側偔偲傕丆忋婰偺専嶕僄儞僕儞摍傪棙梡偡傟偽丆擔杮奺抧偱嶣塭偝傟偨悢懡偔偺栰奜僒儞僾儖乮昗杮乯偺忣曬傪堦偮偺摑崌壔偝傟偨僨乕僞儀乕僗偲偟偰棙梡偡傞偙偲傕壜擻偱偁傞丅屘偵丆偙傟傜偺乽惗暔懡條惈娭楢偺Web僒僀僩乿偼丆崱屻丆懡條惈尋媶偺婎慴偲側傞昗杮僨乕僞傪廤傔偨慡崙乮側偄偟偼悽奅乯婯柾偺峀堟僨乕僞儀乕僗偲偟偰栶棫偮偙偲偑婜懸偝傟傞丅
丂偨偩偟丆偦偺偨傔偵偼偄偔偮偐偺崕暈偟側偗傟偽側傜側偄壽戣偑偁傞丅奺抧偵暘嶶偟偨惗暔懡條惈娭楢Web僒僀僩傪摑崌揑偵棙梡偱偒傞傛偆偵偡傞偨傔偵偼丆偁傞掱搙丆奺Web僒僀僩娫偺楢実側偄偟嫤挷偑昁梫偵側傞丅偦偺偨傔偵栶棫偮偺偑儊僞僨乕僞偲屇偽傟傞傕偺偩偑丆偙偙偱愢柧偡傞偵偼巻悢偑懌傝側偄偺偱丆徻偟偔偼埲壓傪嶲徠婅偄偨偄丅
丂http://protist.i.hosei.ac.jp/GBIF/subjects/metadata.html
丂傑偨丆壜擻側偐偓傝奺Web僒僀僩偺塸岅壔偑朷傑傟傞丅偣偭偐偔廩幚偟偨傕偺傪嶌偭偰傕塸岅偺愢柧偑側偄偲擔杮埲奜偺崙偺恖偵偼尒偰傕傜偊偢丆寢壥偲偟偰惓摉側昡壙偑摼傜傟側偄偙偲偵側偭偰偟傑偆丅懡條惈僨乕僞儀乕僗偺応崌偼丆夋憸偵偮偄偰偺惗暔柤傗娙扨側摿挜偺婰嵹傪塸岅壔偡傞偩偗偱傕悽奅揑偵廫暘棙梡壙抣偺偁傞忣曬採嫙偵側傞偼偢偱偁傞丅
丂偝傜偵丆崱屻嬞媫偺壽戣偵側傞偲巚傢傟傞偺偑丆嶳揷偝傫傕巜揈偟偰偄傞傛偆偵丆奺Web僒僀僩偑偁傞僒乕僶偺梕検晄懌偺栤戣偱偁傞丅惗暔懡條惈娭楢Web僒僀僩偺懡偔偼屄恖偑儃儔儞僥傿傾揑偵嶌偭偰偄傞偺偱丆偦偺岞奐応強偼柉娫偺僾儘僶僀僟偱偁傞応崌偑傎偲傫偳偱偁傞丅偙傟傜偺僒僀僩偼丆撪梕偑廩幚偡傞偵偮傟丆摉慠側偑傜戝検偺夋憸僨乕僞傪書偊崬傓傛偆偵側傞偼偢偩偑丆屄恖偑宱旓偺偐偐傞柉娫偺僾儘僶僀僟忋偱偦偺傛偆側僨乕僞検偺懡偄Web僒僀僩傪堐帩偡傞偺偼柍棟偑偁傠偆丅偦偺偨傔丆幙偺崅偄僒僀僩偵偮偄偰偼岞揑婡娭偑岞奐応強傪採嫙偡傞摍偺懳嶔偑朷傑傟傞丅