| 公開講演会:生物多様性研究・教育を支える広域データベース |
| 原生生物情報サーバ 月井雄二(法政大学) |
| 2 ネット上で公開された情報の評価と保存 | ||
| 2-2 Wayback machine と PageRank | ||
しかし,近年,状況は急速に改善しつつある。「保存」については,Internet Archive(http://www.archive.org/)が,その集めた膨大な情報を昨年末から公開するようになったことの意義が大きい。Internet Archiveとは,ネットワーク上にある情報を人類の貴重な歴史遺産として残すことを目的として,6年前から世界中のありとあらゆるサイトから収集可能なすべてのデータを集めて保存する活動を行っている組織である(これまでに収集したデータは約100テラバイト余!)。従来は,収集した情報の中に著作権やプライバシーに関係するものが含まれているという理由で一般には公開していなかったが,昨年11月頃よりすべてのデータを一般に公開するようになった。このInternet Archiveが集めたデータを閲覧するためのシステムをWayback machineという(http://protist.i.hosei.ac.jp/GBIF/DB_list/About_wayback.html )。
たとえば,「原生生物情報サーバ」の場合は,1997年1月から収集が始まっているが,この当時のURLはhttp://mac2031.fujimi.hosei.ac.jp/Protist_menu.html というものだった。その後,2000年4月に学内ネットワークの大幅な変更があり,その際,当サーバもURLの変更を余儀なくされた(変更後のURLはhttp://protist.i.hosei.ac.jp/Protist_menu.html)。この間もInternet Archiveによるデータ収集は定期的に行なわれ,現在は新旧いずれのURLのデータも閲覧可能になっている(図10)。データベースの内容は頻繁に書き換わっているため,現在,制作者である私の手許には1997年当時のWeb pageのデータは存在しない。だが,Internet Archiveにアクセスすればその当時自分が作ったWeb pageがどんなものだったかを見ることができる(注;初期の頃は画像の収集が不完全だったため,1997年頃のWeb pageの一部は画像のないものもある)。
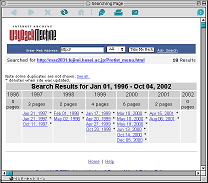
図10a 1997年〜URL変更前のWebデータ URL, http://web.archive.org/web/*/ http://mac2031.fujimi.hosei.ac.jp/Protist_menu.html
|
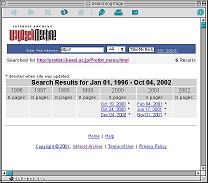
図10b URL変更後〜現在のWebデータ URL, http://web.archive.org/web/*/ http://protist.i.hosei.ac.jp/Protist_menu.html
|
このInternet Archiveの活動には,プライバシーや著作権保護などの問題も残されてはいるが,ネットワークを学術目的で利用しようと考えている者にとっては大変ありがたいサービスといえる。なぜなら,これにより,図書館に収蔵された学術文献と同様,ネットワーク上で公開された情報も安心して論文等で引用できるようになったからである。よって今後はネットワークを学術情報発信のためのメディアとして利用する研究者が増えることが期待される。
一方,評価(情報の品質管理)に関しては,検索エンジン Google (http://www.google.co.jp/)が採用しているPageRankという検索結果を順位付けする仕組みが注目される。検索エンジンには色々なものがあるが,現在,世界でもっとも利用者が多いと言われるのがGoogleである。その理由は,収集した情報量の多さ(2002年12月現在,約31億web pages)と,検索の的確さにある。他の検索エンジンの多くは,収集したWeb pageにあるキーワードの位置や数など,Web pageの内容を分析して,検索結果を順位付けし一覧表示する方式をとっている。しかし,この方式だと,Webサイトの制作者側がキーワードを意図的に書き加えることで検索結果の順位を上げるといった操作ができてしまう。そのため,検索のヒット数が多くなればなるほど,利用者が探している情報が見つかりにくくなる,という欠点がある。
|
これに対して,GoogleのPageRank方式では,各Web pageに対する他のWebサイトからのリンク数を元に順位を決めている(図11)。その際,リンクを張っているサイト自身のPageRankも考慮される。すなわち,PageRankの高いサイトからリンクを張られている場合はそのリンクのポイントは高く,逆に,PageRankの低いサイトからのリンクはポイントが低くカウントされる,という具合である。リンクを張るという行為は,通常,「このサイトは役に立つ」,「他の人にも見せたい」,「参考にした」などの理由で行われるので,リンクには各Web pageを実際に見た利用者(人間)の評価が反映されている,といえる。このため,PageRank方式は,収集した情報が増えれば増えるほど,注目度(評価)のより高いWeb pagesが検索結果の上位に来る傾向があり,利用者は必要な情報を得やすくなる,という優れた特徴をもつ(注3)。
|
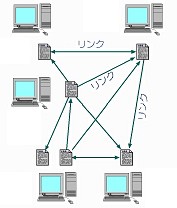
図11 PageRankのしくみ |
| 注3) 的確に検索ができることは利用者にとっては便利でありがたいが,その結果として,一方の情報を発信する側は大変厳しい競争にさらされることになる。例えば,あるキーワードを含むWeb pagesが世界中に数千,数万あったとしても,利用者が閲覧するのは,検索結果の上位10位以内か,多くとも100位程度までであろう。となるとそれ以下にランクされたWeb pagesを見る利用者はほとんどいないことになる。利用者が閲覧してその内容が良いと評価されれば,それはそのWeb pageへのリンク数の増加につながるので,ランクの上位に来たサイトにはますます利用者が集まり,下位のランクのサイトとの差が拡大していくことになる。今後,Googleなどの検索エンジンを利用して情報を探す人が増えるにつれ,こういった情報利用の一極集中はますます進むものと予想される。これはインターネットの出現によってもたらされた「情報のグローバル化」の特徴の一つといえる。 |
ただし,Googleが収集対象としているのは学術情報に限定している訳ではないので,PageRank方式による検索結果のリストの上位に来るものがそのまま学術的価値の高さを反映しているわけではない。とはいえ,検索する際のキーワードとして,他分野では使用されることが少ない専門性の高い学術用語を使えば,その検索結果の上位に来るものはそれなりに学術的にも評価されたWeb pagesであるといえるはずである(参考:http://protist.i.hosei.ac.jp/ProtistInfo/Records/Google.html )。
| I N D E X |