| 公開講演会:生物多様性研究・教育を支える広域データベース |
| 原生生物情報サーバ 月井雄二(法政大学) |
| 1 原生生物情報サーバの紹介 | ||
| 1-3 データベースの作り方 | ||
|
さて,それではどのようにして「原生生物データベース」を作っているかについてだが,これに関しては,すでに以下のURLで一般向けの解説として詳細に述べているのでここではごく簡単に作成手順だけを紹介する。
画像・動画作成支援 まず,野外から採集してきたサンプルを顕微鏡で観察し,それまでに撮影したことのない種類や,あるいはすでに撮影した種であっても,採集地が異なっていたり,形態的な変化がみられるものについては可能なかぎり写真撮影(場合によっては動画も撮影)を行なう(図4)。
|
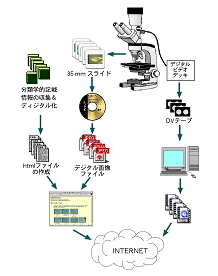
図4 データベースの作り方 |
|
作成したJPEG画像ファイルはフォトCDごとにまとめてデータベースに組み込む。一方,各画像ごとの採集地,年月,撮影者等の基礎データとその生物名(学名;不明な場合もある)からなる記載データを作成し,これと各画像が配置されているURLのデータを合体させた画像表示用のhtml形式のテキストファイルを作成する。
つぎにこのテキストファイルにある各画像の情報(記載情報と画像のURL)を撮影されたサンプル(標本)ごとに切り抜いて,属・種の解説が付いたhtmlファイルに貼付ける。ここで新たに作成されたhtmlファイルは標本ごとの画像を表示させるための「標本Web page」となる。この後,これらの標本Web pageを,標本一覧用の「種Web page」にリンクさせ,さらにそれぞれの種Web pageを種一覧用の「属Web page」へとリンクさせる。こうすることで,利用者は属から種へとリンクを辿って最終的に標本ごとの画像を閲覧できるようになる(図5)。
|
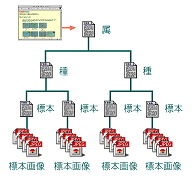
図5 データベースのファイル構成 |
| I N D E X |