Printing vs Internet
 One of the basic features of academic information is that they are permanently preserved at public organizations such as university libraries. Before the Internet era, information produced by researchers was written on papers as manuscripts, and then submitted to journals, where the information was qualified by peer review system. After the qualification, the information was publicized worldwide via printing. Though most journals bought by individuals will be eventually lost, those bought by public institutions (e.g. university libraries) will be kept for long time to serve as references for researchers and others in future.
One of the basic features of academic information is that they are permanently preserved at public organizations such as university libraries. Before the Internet era, information produced by researchers was written on papers as manuscripts, and then submitted to journals, where the information was qualified by peer review system. After the qualification, the information was publicized worldwide via printing. Though most journals bought by individuals will be eventually lost, those bought by public institutions (e.g. university libraries) will be kept for long time to serve as references for researchers and others in future.
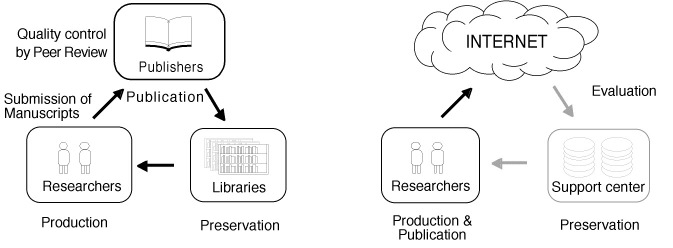
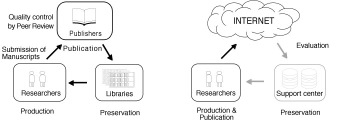
In other words, academic information publicized by printing have been in a well-established social system, i.e., 1) production of information by researchers, 2) their publicization (publication) by publishers after quality control, and 3) their preservation by librarians (Fig. 6).
On the other hand, the Internet as a "new media" is basically different from printing as a "mass media", that is, researchers, or actually anyone, can be both "producers" and "publishers" of their information through the Internet. This will promote information exchange not only within scientist community but also between scientists and other people. However, there is at present neither quality-control nor preservation systems for those information publicized through the Internet, except for genome information.
|
|
Fig. 6 Printing vs Internet
|
In printing, academic information is in a well- established system;
production of the information by researchers,
quality-control and publicization by journal publishers,
and permanent preservation by university libirarians.
In contrast, in the Internet, researchers are able to
|
not only produce but also publicize their information.
But, there is still no public organizations ("Support centers" in this figure)
for qualifying and preserving such information,
so that information publicized on the net can not be at present used as academic resources.
|
In case of genome sciences, all sequence data are centralized into a few computers and maintained by specialists, where the quality control is ensured by the cooperation between DNA database centers and journal publishers where researchers submit their papers analyzing their sequences. And the sequences data will be preserved by the DNA database centers with government supports. This quality-control and preservation system for genome information functions like those of printing (journals), and evaluates sequencing works by genome researchers as their scientific career.
Contrary, centralization of other biological resources such as images is actually impossible as already mentioned, and therefore, they should be databased and publicized on the Internet by researchers themselves. However, the Internet does not have systems for qualifying and preserving such voluntary-delivered information. This situation makes researchers unwilling to publicize their own resources via the Internet, because their works can not be evaluated as scientific career.
|
|